Since speech separation has become a classification problem, speech separation has also become very important. It has been studied in the field of signal processing for several decades, and data-driven methods have also been extensively studied in the field of speech processing.
The goal of speech separation is to separate the target speech from background interference. In signal processing, speech separation is a very basic task type with a wide range of applications, including hearing prosthesis, mobile communication, robust automatic speech, and speaker recognition. The human auditory system can easily separate one's voice from another. Even in a sound environment like a cocktail party, we seem to be able to hear a person's speech in the surround of other people's voice and ambient noise without any difficulty. So the problem of speech separation is often called the "cocktail party problem", which was proposed by Cherry in his famous paper in 1953.
The most important way of communication for human beings is language. For us, it is crucial to separate speech from background interference. Interested speech or target conversations are often disturbed by unwanted noise from other sources and reverberation from surface reflections. Although humans can easily separate speech, it turns out that building an automated system that rivals the human auditory system is challenging in this basic task. In Cherry's 1953 book, he observed: "There is no machine that can solve the "cocktail party problem" so far." Unfortunately, although the recent research progress mentioned in this article has begun to solve this problem, but in our In this field, his conclusion has been correct for more than 60 years.
Speech separation is very important and has been studied in the field of signal processing for decades. Depending on the number of sensors or microphones, the separation method can be divided into a mono method (single microphone) and an array method (multiple microphones). Two traditional methods of mono separation are speech enhancement and computational auditory scene analysis (CASA). The speech enhancement method analyzes all the data of speech and noise, and then estimates the noise by the noise estimation of the noisy speech. The simplest and most widely used enhancement method is the spectral subtracTIon, in which the power spectrum of the estimated noise is removed from the noisy speech. To estimate background noise, speech enhancement techniques generally assume that the background noise is stable, that is, its spectral characteristics do not change over time, or at least are more stable than speech. CASA builds on the perceptual theory of auditory scene analysis, using grouping cue such as pitch and onset. For example, the tandem algorithm performs speech separation by exchanging pitch estimates and pitch-based clustering.
An array of two or more microphones uses different methods of speech separation. Beamforming, or spatial filters, enhance the signal arriving from a particular direction with an appropriate array structure, thereby reducing interference from other directions. The simplest beamforming is a delay-superimposition technique that adds signals from multiple microphones in the target direction in the same phase and cuts signals from other directions based on the phase difference. The amount of noise reduction depends on the spacing, size, and structure of the array, and as the number of microphones and array length increases, the amount of reduction increases. Obviously, spatial filters are not applicable when the target source and the interferer are co-located or are in close proximity. In addition, in the echo scene, the effect of beamforming is greatly reduced, and the determination of the direction of the sound source becomes blurred.
A recently proposed method treats speech separation as a supervised learning problem. The initial formation of supervised speech separation is inspired by the concept of TIME-frequency (TF) masking in CASA. The primary goal of CASA is the ideal binary mask (IBM), which indicates whether the target signal controls a TF unit in the time-frequency representation of the mixed signal. Hearing studies have shown that ideal binary masks can significantly improve the ability of normal hearing (NH) and hearing impaired (HI) to understand speech in noisy environments. With IBM as the computational goal, speech separation becomes a binary classification problem, which is a basic form of supervised learning. In this case, IBM is used as the target signal or objective function in training. In testing, the purpose of learning machines is to estimate IBM, which is the first training goal to monitor speech separation.
Since speech separation has become a classification problem, data-driven methods have been extensively studied in the field of speech processing. Over the past decade, overcoming speech separation has dramatically improved state-of-the-art performance through the use of large training data and increased computing resources. Supervised separation has benefited a lot from the development of deep learning, which is also the subject of this paper. Supervised speech separation algorithms can be broadly divided into the following sections: learning machines, training objectives, and acoustic features. In this article, we first review these three parts. Then introduce representative algorithms, including mono methods and array-based algorithms. Generalization as a special topic for monitoring speech separation will also be discussed in this article.
To avoid confusion, we need to clarify several related terms used in this article. Speech separaTIon or speech segregaTIon (speech separation) refers to the task of separating target speech from background interference, which may include non-speech noise, interfering speech, or both, and indoor reverberation. In addition, the "cocktail party problem" also refers to speech separation. Speech enhancement or denoising refers to the separation of speech and non-speech noise. If it is a speech separation problem for multiple speakers, we use the term "speaker separation."
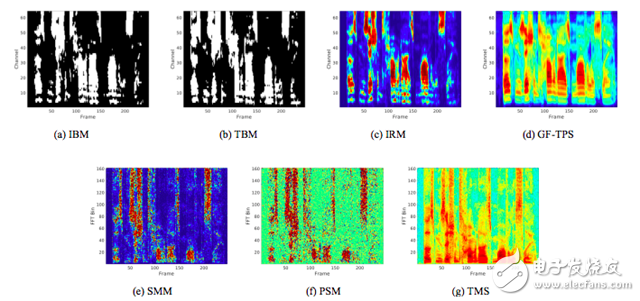
Figure 1. Different training target diagrams for TIMIT audio data mixed with -5 dB SNR factory noise.
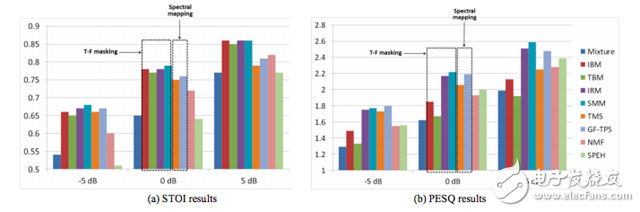
Figure 2. Comparison of training results using different training objectives. (a) STOI. (b) PESQ. Factory noise with a signal-to-noise ratio of -5dB, 0dB, and 5dB is mixed with clear speech.
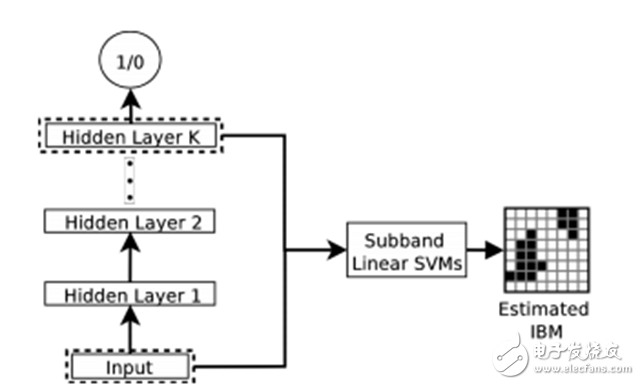
Figure 3. Graphical representation of feature learning by DNN using a linear SVM to estimate IBM values ​​for learned features.

Figure 4. Diagram of a two-stage DNN for speech separation.
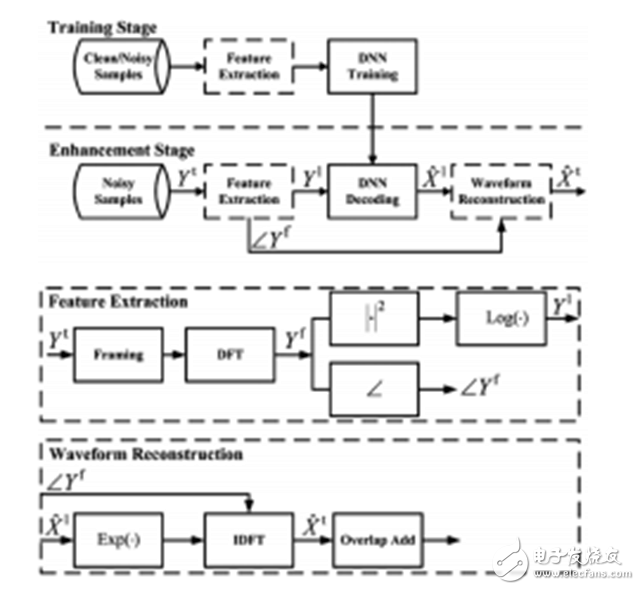
Figure 5. Graphical representation of a DNN-based spectrum mapping method for speech enhancement.
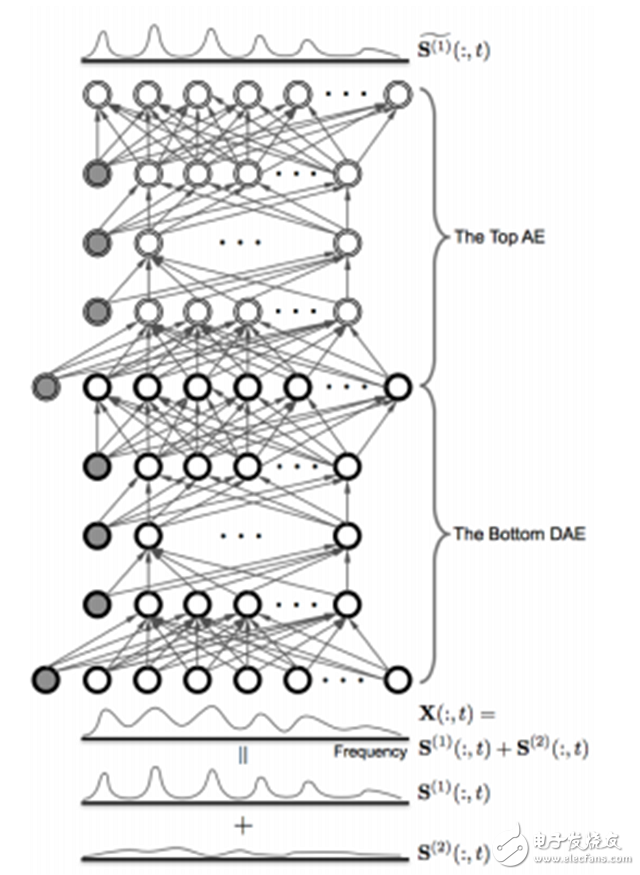
Figure 6. Speech-enhanced DNN architecture with an autoencoder configured for unsupervised debugging. The AE is stacked on top of the DNN as a purity detector to estimate clear speech from the DNN.
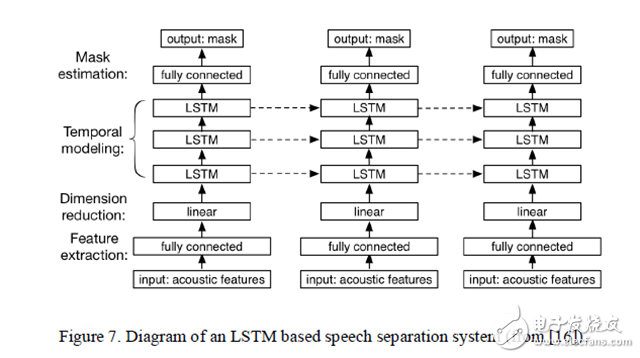
Figure 7. Structured display of an LSTM-based speech separation system.
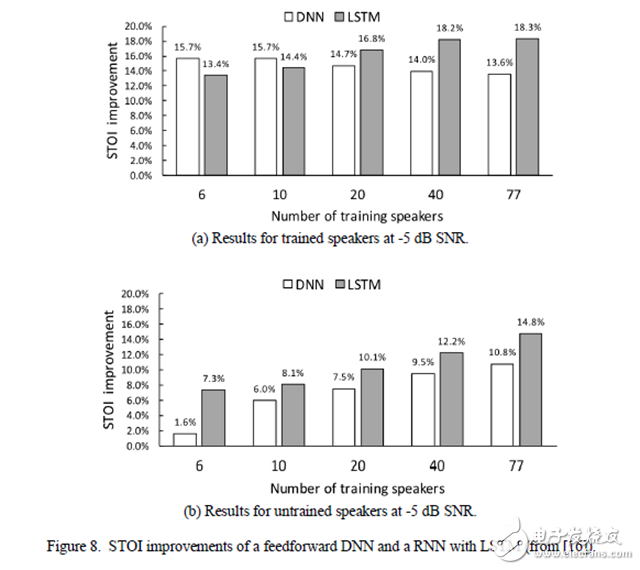
Figure 8. STOI improvements for feedforward DNN and LSTM-based RNN. (a) The result of a trained speaker with a signal-to-noise ratio of -5 dB. (b) The result of an untrained speaker with a signal-to-noise ratio of -5 dB.
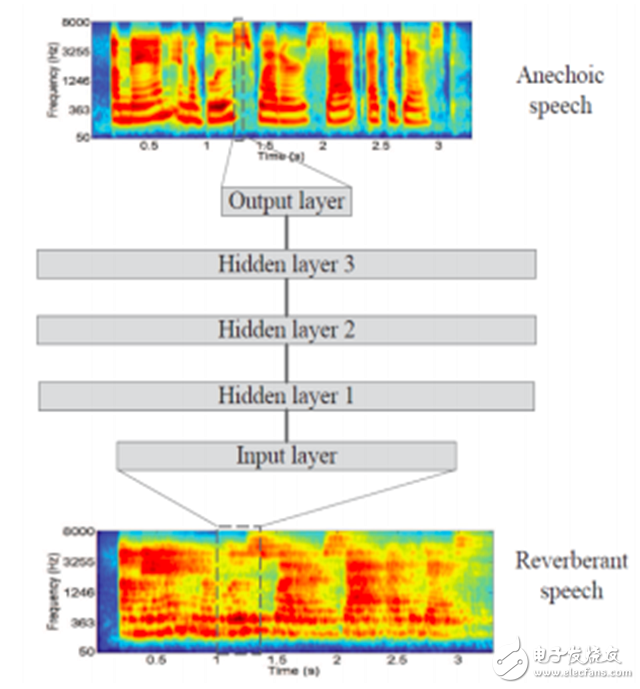
Figure 9. Schematic diagram of speech reverberation reduction DNN based on spectral mapping [45].
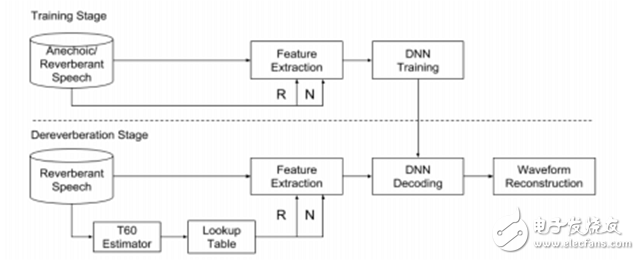
Figure 10. Reverberation time response DNN structure diagram for speech reverb reduction 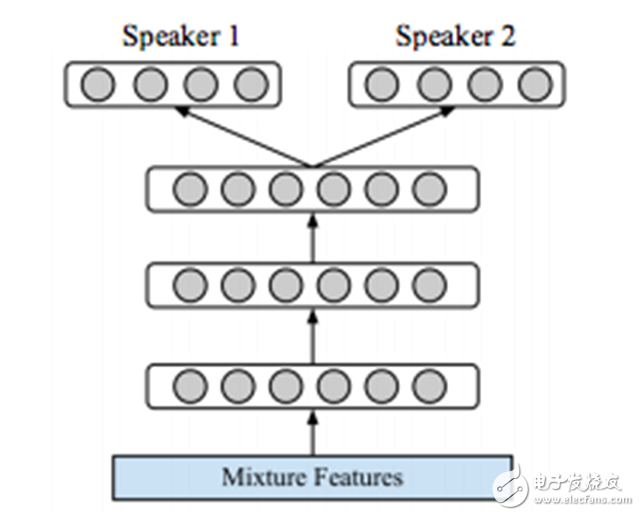
Figure 11. Graphical representation of two speaker separation methods based on DNN.
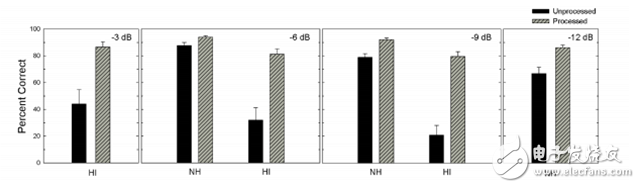
Figure 12. Average sharpness score and standard deviation of a hearing-healing person and a hearing-impaired person listening to the target statement of the mixed-interference statement and separating the target sentence from it. The graph shows the percentage of correct rate percentages for four different target-interference ratios.
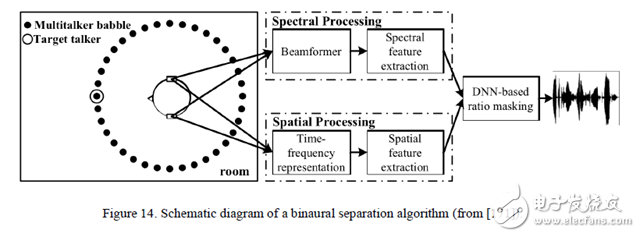
Figure 14. Structure diagram of the two-channel separation algorithm.
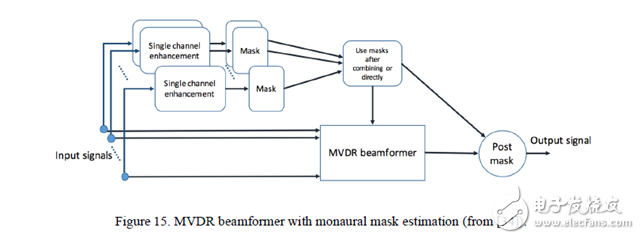
Figure 15. MVDR beamformer for mono mask estimation.
The latest Windows has multiple versions, including Basic, Home, and Ultimate. Windows has developed from a simple GUI to a typical operating system with its own file format and drivers, and has actually become the most user-friendly operating system. Windows has added the Multiple Desktops feature. This function allows users to use multiple desktop environments under the same operating system, that is, users can switch between different desktop environments according to their needs. It can be said that on the tablet platform, the Windows operating system has a good foundation.
Windows Tablet,New Windows Tablet,Tablet Windows
Jingjiang Gisen Technology Co.,Ltd , https://www.gisentech.com