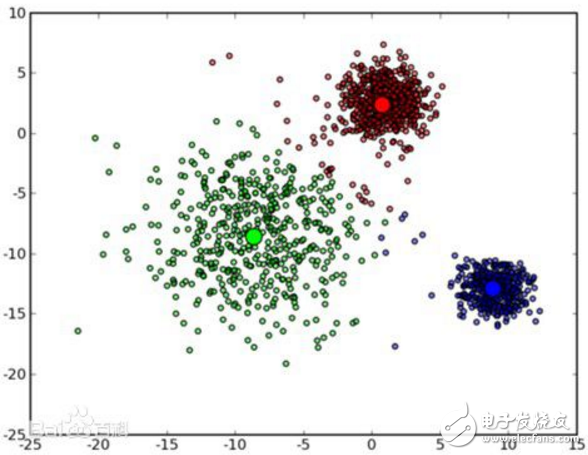
The K-means algorithm is a typical distance-based clustering algorithm. The distance is used as the evaluation index of similarity. The closer the distance between two objects is, the greater the similarity. The algorithm considers clusters to be composed of objects that are close together, thus making compact and independent clusters the ultimate goal.
The selection of k initial class cluster center points has a great influence on the clustering result, because in the first step of the algorithm, any k objects are randomly selected as the center of the initial cluster, initially representing a cluster. The algorithm reassigns each object to the nearest cluster for each object remaining in the dataset in each iteration based on its distance from each cluster center. After all the data objects have been examined, an iterative operation is completed and the new cluster center is calculated. If the value of J does not change before and after an iteration, the algorithm has converged.
1) randomly select K documents from N documents as centroid
2) Measure the distance to each centroid for each of the remaining documents and classify it into the nearest centroid class
3) Recalculate the centroids of the various classes that have been obtained
4) Iterate 2 to 3 steps until the new centroid is equal to or less than the specified threshold, and the algorithm ends.
details as follows:Enter: k, data[n];
(1) Select k initial center points, such as c[0]=data[0],...c[k-1]=data[k-1];
(2) For data[0]....data[n], compared with c[0]...c[k-1], respectively, assuming that the difference from c[i] is the least, it is marked as i;
(3) For all points marked i, recalculate c[i]={the sum of all data[j] marked with i}/marked as i;
(4) Repeat (2) (3) until all c[i] values ​​change less than a given threshold.
The advantages of the K-means algorithm are: First, the algorithm can prune the tree according to the category of fewer known cluster samples to determine the classification of the partial samples; secondly, to overcome the inaccuracy of a small number of sample clusters, the algorithm itself With optimized iterative function, iteratively corrects the pruning to determine the clustering of partial samples on the already obtained clusters, and optimizes the unreasonable classification of the initial supervised learning samples; thirdly, it can reduce the total for only some small samples. Clustering time complexity.
The disadvantages of the K-means algorithm are: First, K is given in advance in the K-means algorithm, and the selection of this K value is very difficult to estimate. In many cases, it is most appropriate to know in advance how many categories a given data set should be divided into. Secondly, in the K-means algorithm, an initial partition is first determined based on the initial cluster center, and then the initial partition is optimized. The selection of this initial clustering center has a great influence on the clustering results. Once the initial value is not well selected, effective clustering results may not be obtained. Finally, the algorithm needs to continuously adjust the sample classification and continuously calculate and adjust. After the new cluster center, so when the amount of data is very large, the time cost of the algorithm is very large.
The K-means algorithm may lead to different results for different initial values. Solution:
1. Set some different initial values, compare the final operation results, until the results tend to end
2. Many times, it is most appropriate to know in advance how many categories a given data set should be divided into. By automatically merging and splitting the classes, a reasonable number of types K is obtained, such as the ISODATA algorithm.
Other improved algorithms for the K-means algorithm are as follows:
1. k-modes algorithm: realizes rapid clustering of discrete data, retains the efficiency of k-means algorithm and extends the application range of k-means to discrete data.
2. k-Prototype algorithm: It is possible to cluster data of two kinds of discrete and numerical attributes, and define a dissimilarity metric calculated by both logarithmic and discrete attributes in k-prototype.
The first clustering method that everyone is exposed to is the K-means clustering. The algorithm is very easy to understand and easy to implement. In fact, almost all machine learning and data mining algorithms have their advantages and disadvantages.
(1) sensitive to outliers and isolated points;
(2) k value selection;
(3) the selection of the initial cluster center;
(4) Only spherical clusters can be found.
For the reason of these 4 points, the reader can think for himself and it is not difficult to understand. In response to the above four shortcomings, the improvement measures are introduced in turn.
Improvement 1First, for (1), how to solve the problem of outliers and isolated points? The LOF algorithm of outlier detection is mentioned. By removing the outliers and then clustering, the influence of outliers and isolated points on the clustering effect can be reduced.
Improvement 2The problem of k-value selection, the k-value adaptive optimization method of k-Means algorithm is mentioned in the master's thesis of Anhui University Li Fang. The method will be summarized below.
First, the algorithm improves on the following main disadvantages of the K-means algorithm:
1) k must be given first (the number of clusters to be generated), and the k value is difficult to select. It is not known in advance which class the given data should be divided into.
2) The choice of the initial cluster center is a problem with K-means.
The idea of ​​the algorithm designed by Li Fang is as follows: You can get a clustering center by a K-means algorithm by giving a suitable value to k at the beginning. For the obtained cluster center, according to the distance of the obtained k clusters, the nearest class is merged, so the number of cluster centers is reduced, and when it is used for the next cluster, the corresponding number of clusters is also reduced. Small, and finally get the appropriate number of clusters. It is possible to determine the number of clusters by a judgment value E to get a suitable position to stop without continuing to merge the cluster centers. The above cycle is repeated until the evaluation function converges, and finally the clustering result of the better cluster number is obtained.
Improvement 3Optimization of the selection of the initial cluster center. In one sentence, it is summarized as: select K points as far as possible from the batch distance. The specific selection steps are as follows.
First randomly select a point as the first initial cluster center point, then select the point farthest from the point as the second initial cluster center point, and then select the point with the closest distance from the first two points as the point The center point of the third initial cluster, and so on, until the K initial cluster center points are selected.
There is still a solution to this problem. I have used it before. Students familiar with weka should know that there is an algorithm called Canopy algorithm for clustering in weka.
The hierarchical clustering or Canopy algorithm is used for initial clustering, and then the center point of these clusters is used as the initial cluster center point of the KMeans algorithm. This method is also very effective for the selection of k values.
Improvement 4The root cause of only getting spherical clusters is the way the distance is measured. In the improvement and application of the K_means clustering method of the master's thesis of Li Huizhen, the improvement based on the two measures is mentioned. After the improvement, the non-negative and elliptical data can be found. However, for this improvement, personally, it is not a good solution to the problem of K-means in this shortcoming. If the data set has irregular data, it is more suitable through density-based clustering algorithm, such as DESCAN algorithm.
Brake Disc For LEXUS
Lexus Brake Disc,Lexus Auto Brake Disc,Lexus Car Brake Disc,Lexus Automobile Brake Disc
Zhoushan Shenying Filter Manufacture Co., Ltd. , https://www.renkenfilter.com